초음파 광물 예측 데이터 sonar.csv 파일을 이용해 딥러닝을 해볼 것이다.
데이터는 그냥 sonar.csv를 검색하면 나오는 kaggle 사이트에서 가져왔다.

이전에 했던 것처럼 딥러닝 모델을 설계해서 작동시켰다.
200 epoch를 돌렸는데 정확도가 아예 1.0000이 나온다.
이런 현상을 과적합이라고 한다.
과적합을 설명하는 가장 적절한 그림이다.
과적합은 모델이 학습 데이터셋 안에서는 높은 정확도를 보이지만 새로운 데이터에 적용하면 잘 맞지 않는 것이다.
빨간색과 하얀색을 나누는 모델을 학습시켰다고 할 때, 과적합이 일어나면 주어진 샘플에 대해서는 정확히 맞게 선이 그어졌지만
너무 주어진 데이터에만 최적화 되어있다.
조금 다른 느낌이긴 하지만 이해를 돕기 위해서 개인적인 비유로 설명하자면, 1 2 3 4 다음에 올 수를 맞추라는 문제에서 5를 얘기하는 것이 아니라 i번째 수 = (i-1)(i-2)(i-3)(i-4)+i 라는 공식을 만들어서 5번째 수를 29라고 하는 것과 비슷한 느낌이다.
주어진 데이터 1 2 3 4에는 완벽히 들어맞지만 새로운 데이터 5에는 전혀 다른 결과를 내버리는 것이다.
과적합은 층이 너무 많거나 변수가 복잡해서 발생하기도 하고 테스트셋과 학습셋이 중복될 때 생기기도 한다.
은닉층 개수에 따른 정확도이다.
은닉층이 너무 많아지면 학습셋의 예측률은 100이 되지만 테스트셋의 예측률은 떨어진다.
과적합을 방지하기 위해서는 먼저 데이터를 학습셋과 테스트셋으로 구분하여 학습을 시켜야 한다.
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,test_size=0.3,random_state=seed)이렇게 30%의 데이터를 테스트셋으로 구분하고
model.fit(X_train,Y_train,epochs=130,batch_size=5)
print("\n Accuracy: %.4f" %(model.evaluate(X_test,Y_test)[1]))학습은 학습셋으로, 테스트는 테스트셋으로 하면 된다.
학습 과정에서 정확도는 1.0000이 나오지만 마지막에 테스트셋으로 테스트한 결과는 0.8209가 나온다.
학습시킨 모델을 저장하고 불러오기 위해서는 model.save와 load_model을 사용하면 간단하게 할 수 있다.
model.fit(X_train,Y_train,epochs=130,batch_size=5)
model.save('my_model.h5')
del model
model = load_model('my_model.h5')
print("\n Accuracy: %.4f" %(model.evaluate(X_test,Y_test)[1]))이렇게 하면 된다.
테스트를 더 정확하게 설정할수록 모델은 잘 작동한다.
하지만 데이터가 충분하지 않을 때는 테스트를 정교하게 할 수 없다.
앞서 했던 방식은 데이터의 30%만을 테스트셋으로 사용할 수 있었다.
이런 단점을 보완하기 위해 나온 방법이 k겹 교차 검증이다.
k겹 교차 검증은 데이터를 여러 개로 나누어 하나씩 테스트셋으로 사용하고, 나머지를 모두 학습셋으로 사용하는 방법이다.
5겹 교차 검증의 예시이다.
이렇게 하면 데이터의 100%를 테스트셋으로 사용할 수 있다.
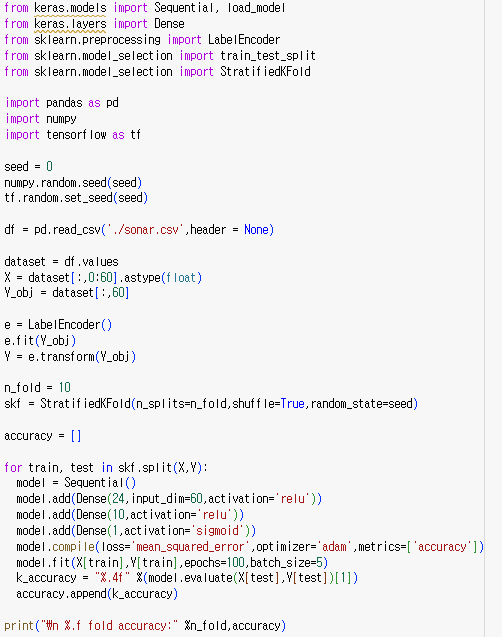
10겹 교차 검증을 이용한 딥러닝 모델 코드이다.

10번의 테스트 값들이 잘 출력되는 것을 확인할 수 있다.
'인공지능' 카테고리의 다른 글
| 모두의 딥러닝 - 12장(다중 분류 문제 해결하기) (0) | 2025.03.18 |
|---|---|
| 모두의 딥러닝 - 11장(데이터 다루기) (0) | 2025.03.18 |
| 모두의 딥러닝 - 10장(모델 설계하기) (0) | 2025.03.17 |
| 모두의 딥러닝 - 6장 ~ 9장(신경망) (0) | 2025.03.17 |
| 모두의 딥러닝 - 5장(로지스틱 회귀) (0) | 2025.03.05 |



